
Automated Compute Resource Optimization
for Kubernetes
Eliminate waste and manual effort
“We’ve leveraged Kubex to identify 30% savings in our K8s environment and are executing the actions to achieve those savings. We are planning to automate right-sizing and also leverage Kubex to have transparency on our GPU utilization to drive optimizations.”
SREs, Platform Owners and FinOps teams are succeeding and saving $millions.
Slash Cost, Improve Reliability and Spend Less Time Managing
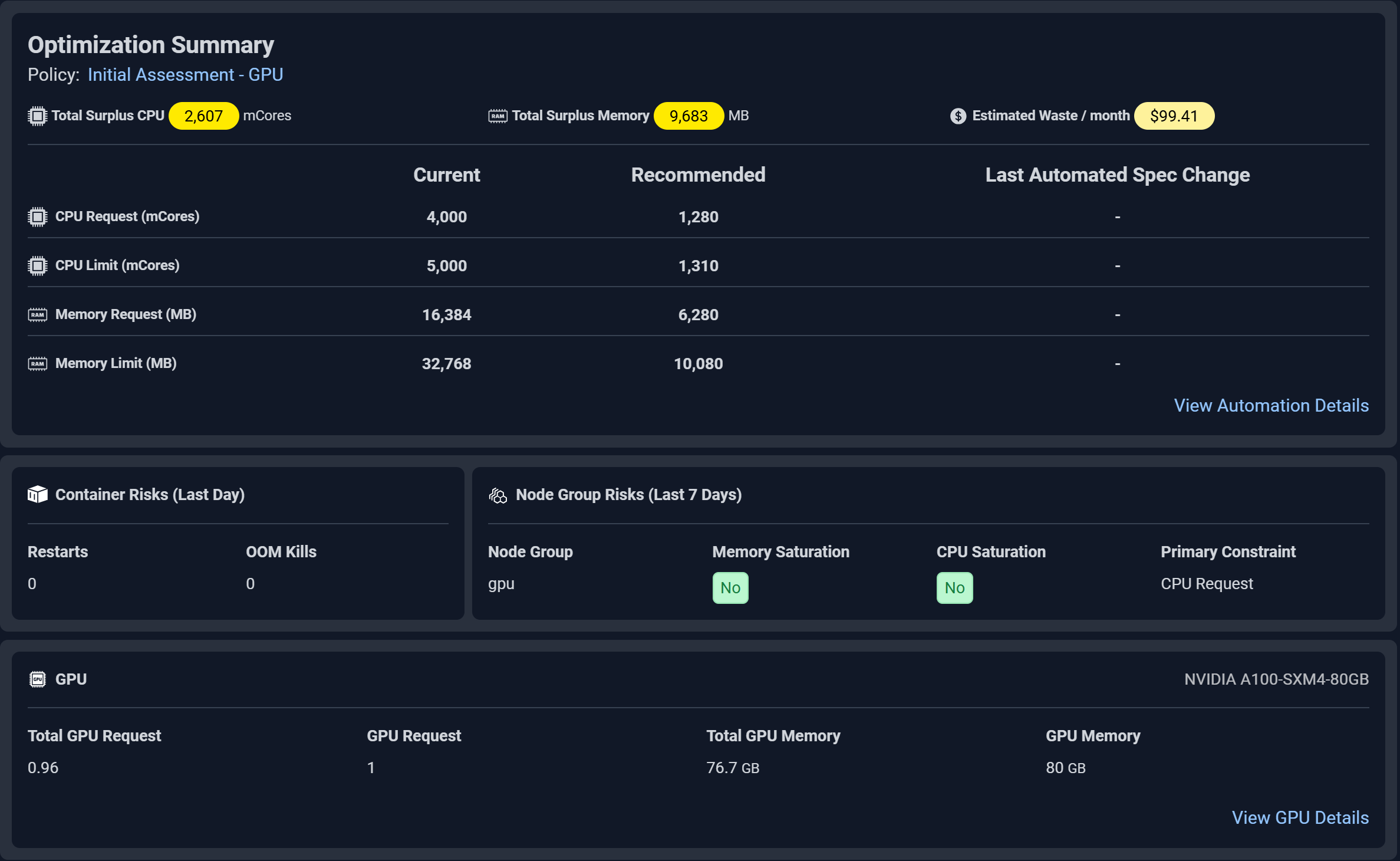
Predictive Container Sizing
Right-size resources automatically with ML-driven accuracy.
- Learns real workload behavior to recommend ideal CPU, memory, and GPU requests
- Eliminates over-provisioning without risking performance
- Continuously updates sizing as applications evolve
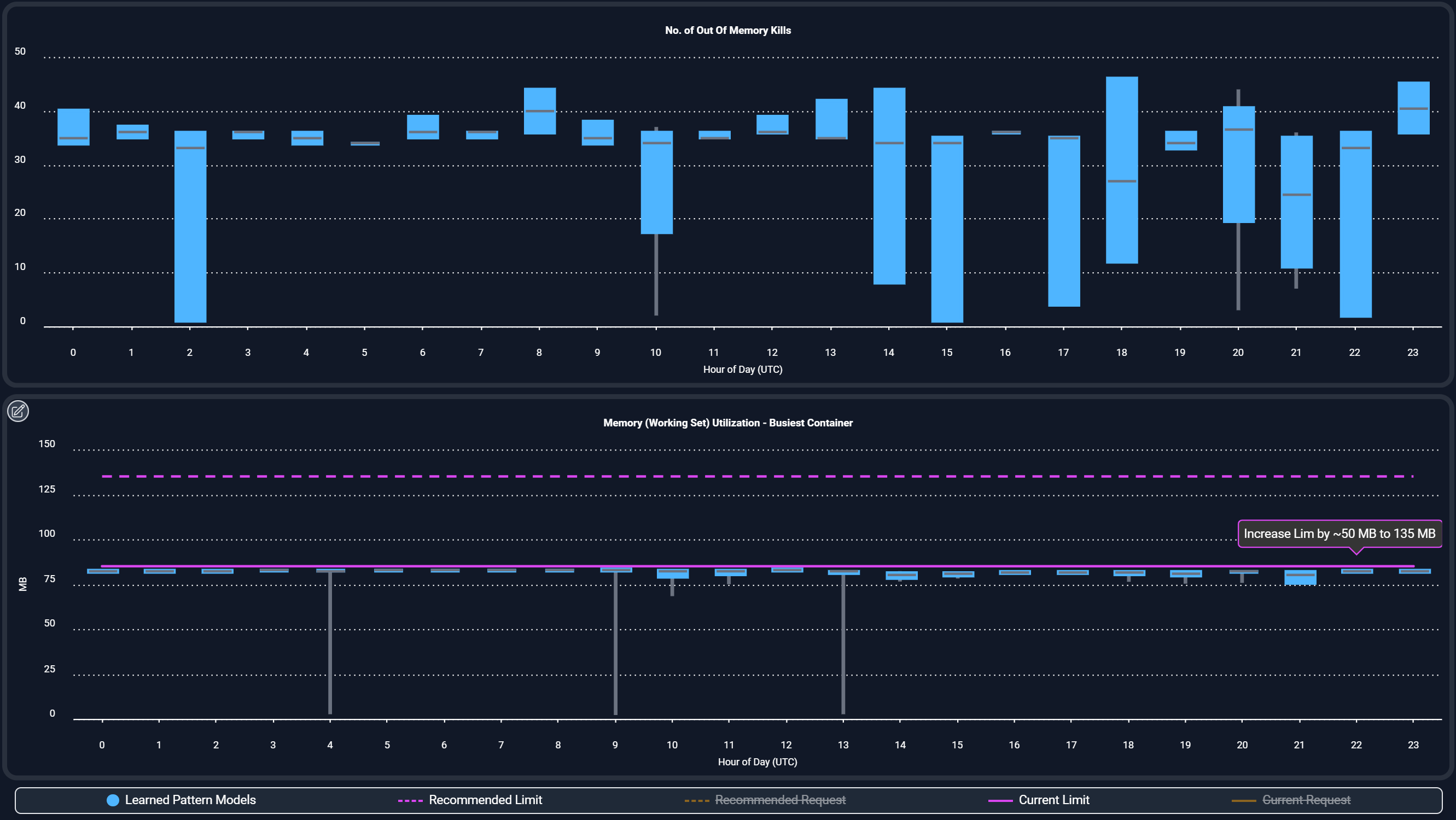
OOM & Throttling Prevention
Stop crashes and performance degradation before they happen.
- Detects pods at risk of OOM kills or CPU throttling
- Recommends limit adjustments to stabilize workloads
- Ensures consistent SLA performance under peak demand
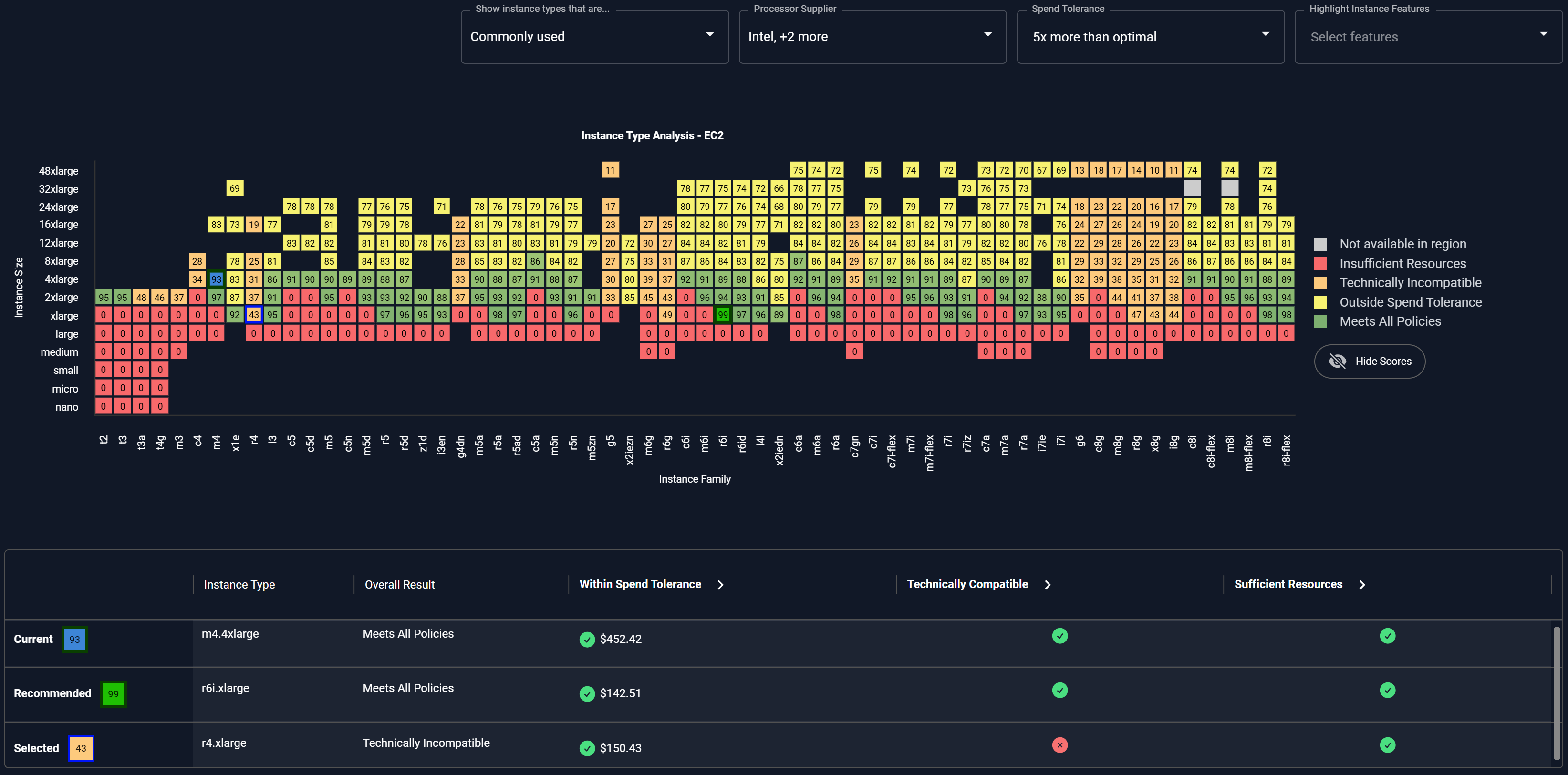
Node Spec Optimization
Run more efficiently by aligning nodes to actual workload needs.
- Matches cloud or on prem node types and sizes to real usage patterns
- Reduces waste from oversized or inefficient node instance selection
- Improves cluster density and lowers overall compute cost
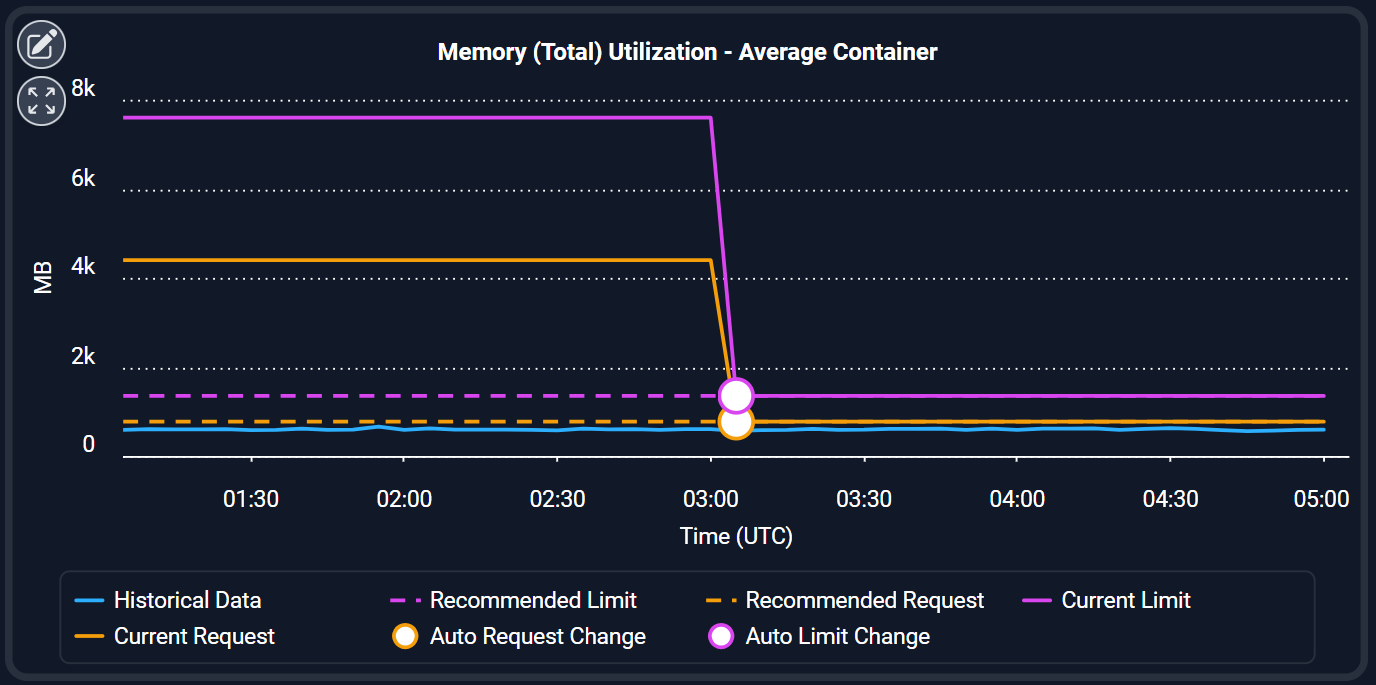
Full Automation
Let the platform handle optimization — hands-free.
- Automatically applies vetted optimization actions at scale
- Integrates smoothly with GitOps and CI/CD workflows
- Removes manual tuning and reactive operational overhead
Kubex AI Agent working as part of your team
Agentic AI combines Kubex’s market leading optimization intelligence with a chat-based AI assistant that makes the power of Kubex available to everyone.
- Talk to Kubex with natural-language queries to ask questions about infrastructure, workloads or resource usage
- Navigate by asking for details about specific containers, nodes or automation events and Kubex Agent will take you there
- Enhanced sharing and collaboration: responses can return interactive tables with deep links which can easily be exported for sharing
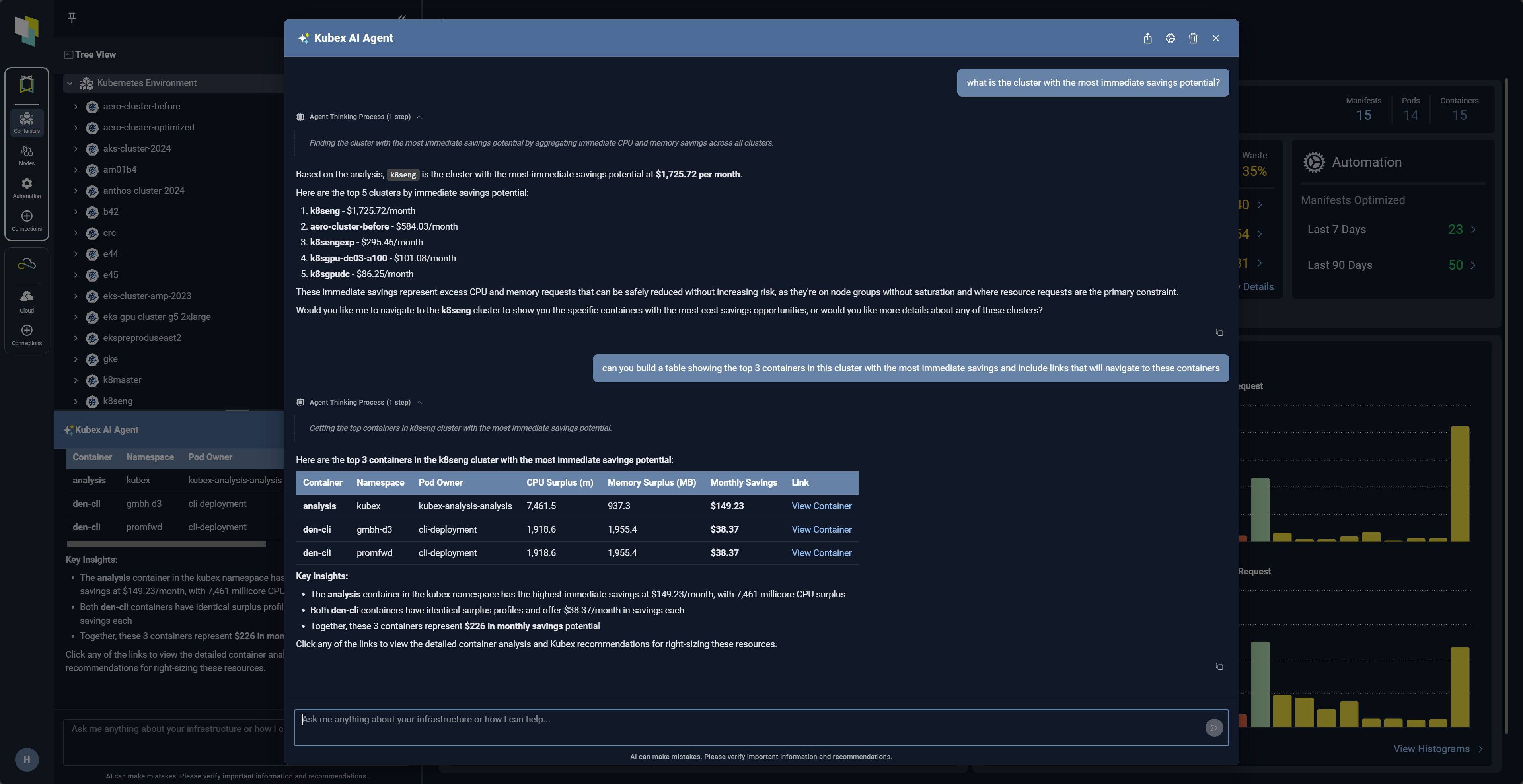
See the benefits of optimized
Kubernetes Resources
AI-driven analytics that precisely determine optimal resource settings for Kubernetes.
FAQs


